前几天为了组会重新读了一下CS285中信任域的推理部分,重新做了一版PPT,但很遗憾最后没有时间讲,于是整理一下形成文章。
策略梯度回顾
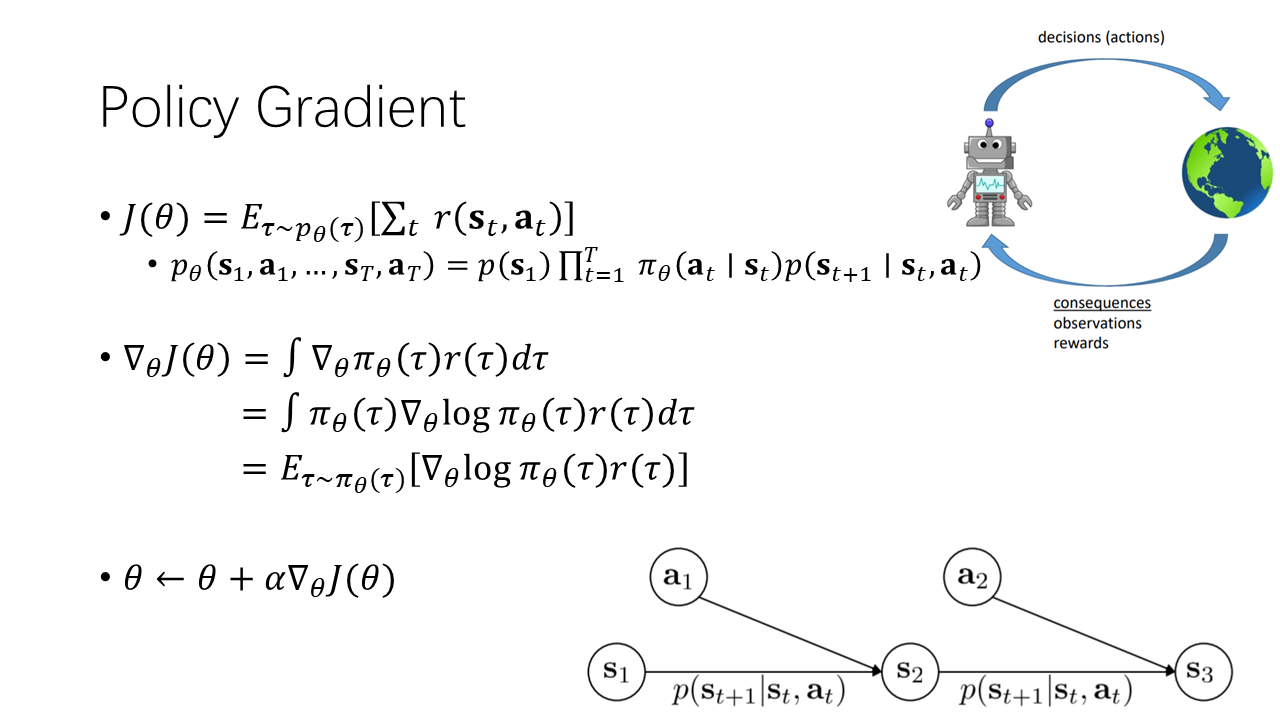
强化学习的过程为:智能体做出决策与环境交互,环境为智能体返回状态(观测)与奖励,智能体通过交互不断形成数据,从经验中进行学习。策略梯度方法对策略进行建模,并通过目标函数对策略模型进行梯度更新。目标函数即我们希望最大化的值,在强化学习任务下,这个值即为轨迹回报的期望。期望即以概率为权重积分,策略就包含在轨迹概率中。也就是说对于策略不同参数值,由这个策略做决策得到的轨迹概率分布也不同,我们希望改变使得高回报的轨迹概率升高(上图中第一组公式)。
对目标函数进行求导,中与相关的部分只有,求导时用到了一个公式。观察得到的梯度公式,如果去掉其中的,则这个梯度即为求极大似然时的梯度。从这个角度可以理解一下策略梯度,它也是对自己经验数据的一个极大似然,只不过在其中加入了监督项。监督项的意义是,增大那些回报高的轨迹的概率,同时降低那些回报低的轨迹的概率。(第二组公式)
PG算法即对策略参数进行梯度更新,其中更新的步长是一个比较小的值,通过这种方式不断对策略进行评估与更新。(第三个公式)
策略梯度存在的问题
方差过大
首先方差指的是策略梯度的方差,策略梯度方差大是实践中遇到的问题。由于目标函数中存在期望,期望要通过采样完成,由于采样数量有限,期望一定会受到不同采样的影响,且影响很大。若采样个数增多,则这个方差也会降低。
策略梯度的方差越大,则策略越难以达到收敛。因此需要想办法解决方差过大的问题。
降低方差的方法:
因果律
加入baseline
因果律

因果律方法基于一个考量:当前t时刻的决策不会影响到时刻的奖励。之前说过回报是监督信息,既然之前时刻的奖励不会受此时刻决策印象,就应该在监督中把它们去除。通过这种方式将回报变为reward to go,一个类似Q值的回报。这种方式成功降低了方差,但是还不够。
加入baselines

在之前的步骤中我们成功将梯度化成上图第一个式子,通过因果律将轨迹回报变成了。但此时的只是一条轨迹的reward to go,这其实是一种对reward to go的单样本估计,因此随机性很大,方差也很大。于是将值变成期望形式,如上图第二个式子,使用这个值也能有效降低梯度方差。
加入baselines可以降低方差,且结果无偏。baselines值可以选择平均奖励,也就是采样值的平均值,这是快速且方便的选择。值是对的一个加权平均,也是奖励的平均值,虽说不是最好的baselines,但也足够了。

而真正的最优baselines在CS285课程中进行过推导(如上图),可以看到最终的b其实就是以梯度大小为权重的奖励期望,这个计算起来过于复杂,但我们可以领会其中思想,即真正最优的baselines应该视梯度关于各参数的重要性来定,也就是对模型中的每一个不同参数有着不同的baselines。
整理一下

在将baselines换为V值后,监督就从奖励变成了Advantage,Advantage是某个动作相对于平均动作的回报优势。但这个V值应该如何获得呢?
Actor-Critic

我们用一个神经网络来拟合价值函数。在拟合过程中,真实值标签只能从采样中获得,然而在获得值时,我们不是每次都能回到这个状态,因此只能用一条路径来拟合V值。神经网络的泛化性可以弥补一些这部分的不足,接近的可以互相影响,互相作为参照。
这个神经网络即为Actor-Critic架构中的Critic部分,策略决策者则为Actor。Actor与环境交互获得数据,Critic对Actor进行评估,最终Actor根据评估对自身模型进行更新。
我们将Q,V,A都用V值来表示,得到了最终的策略梯度(上图最后一式)。这里的A只是其中的一种方式,不同critic对优势函数的评估方式也不同,PPO中利用了GAE,一种介于蒙特卡洛方法与这个A之间的方法,之后再提。
我们从最初的奖励期望梯度到现在,从一个无偏/高方差的梯度,变为一个有偏/低方差的梯度。
PG可行吗?
目标函数差值
介绍完PG,我们回头来看一下PG是否可行,或者说PG在什么情况下可行。
PG的梯度更新公式为,如果我们将PG看为一种策略迭代即用替代。当然策略迭代实际只是推导Q迭代的中间过程,在这里借用这个算法来进行之后的推导。
我们希望更新后的参数在目标函数上有更好的表现,即最大化一个差值目标函数,下面要证明这个目标函数的梯度即为我们在PG中推导得出的梯度。
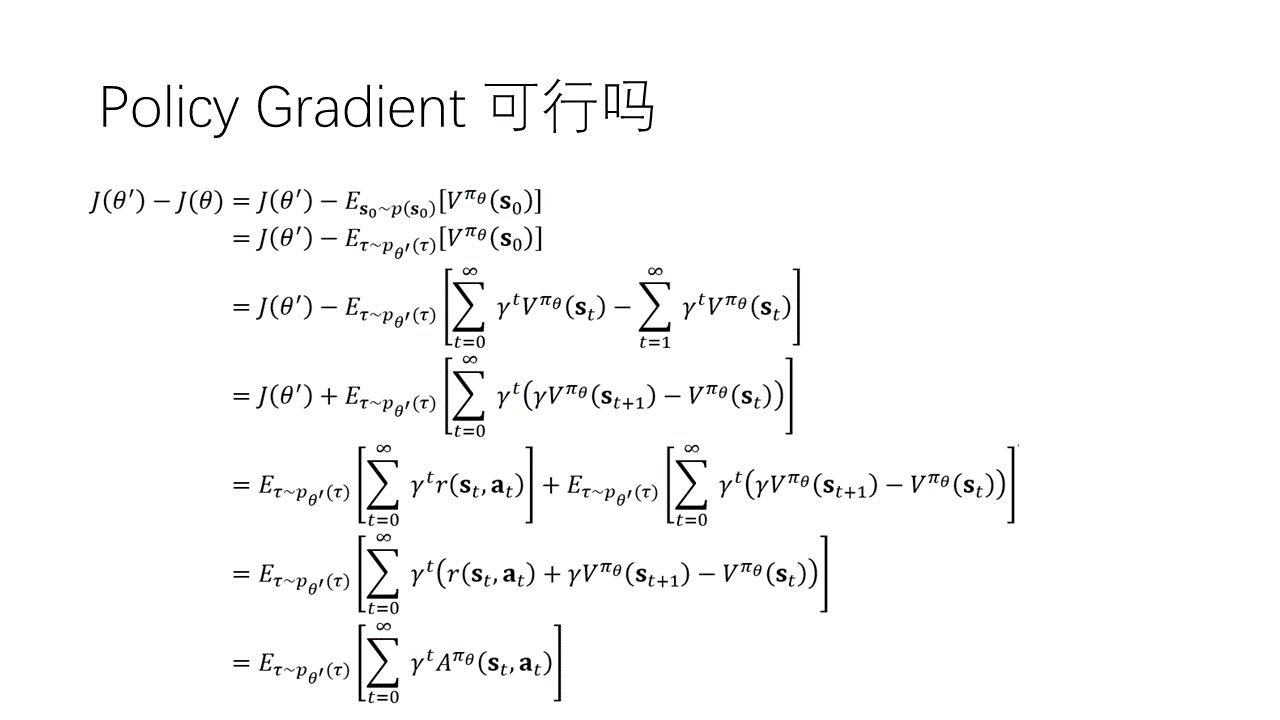
第一行中等于在下初始状态的价值期望。在第一行到第二行的推导中,与是一样的,前者与的值无关,而后者中每一条轨迹都经过,且初始状态概率不会改变,因此可以后者替换前者。之后的推导过程比较直观易懂。
最终得到的式子的确与下的优势函数有关,但注意期望中的是来自的。然而我们在PG中只能从中采样,因为还是未知的。因此接下来就要将其中的换成,当然不能直接换,要利用重要性采样。
重要性采样
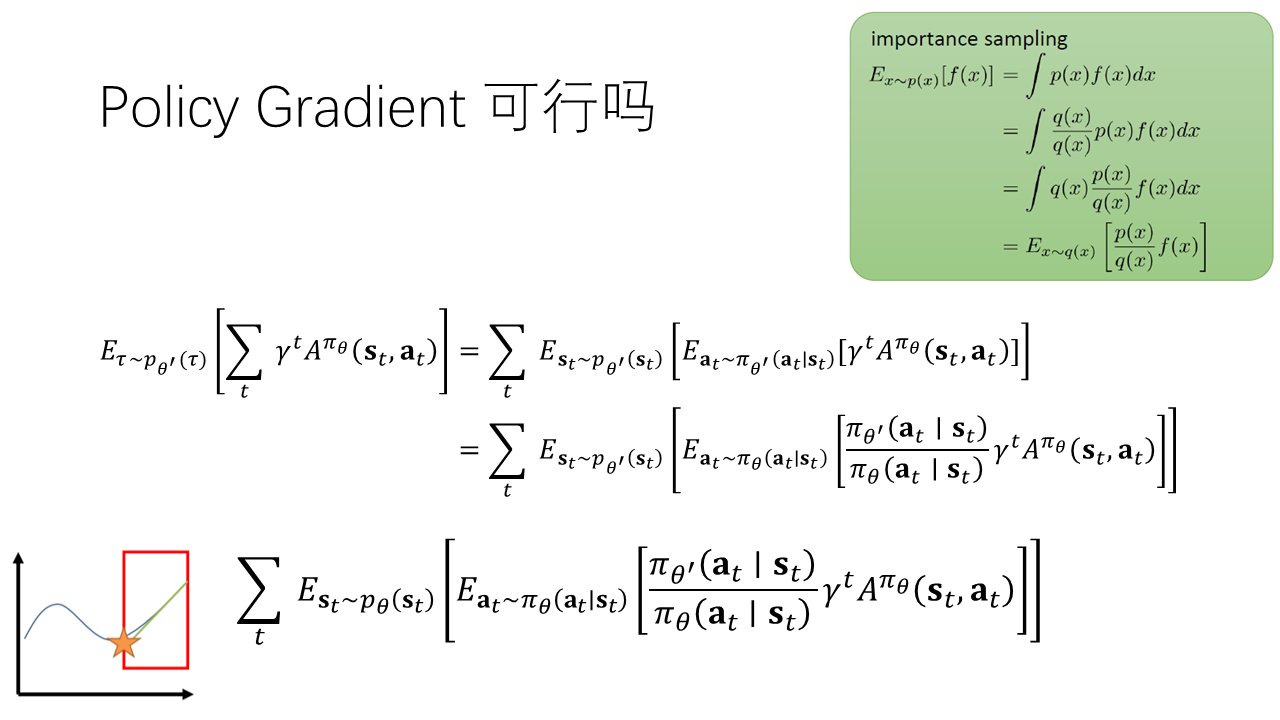
将打开,对动作进行重要性采样,将动作换成了下的动作,但仍为下的期望。如果真的能将期望换成最下面这种形式,那我们就成功证明了PG是正确的,即可以通过对优势进行评估来对策略进行更新。那么我们只能默认,也就是说在两个参数下状态的分布相似。
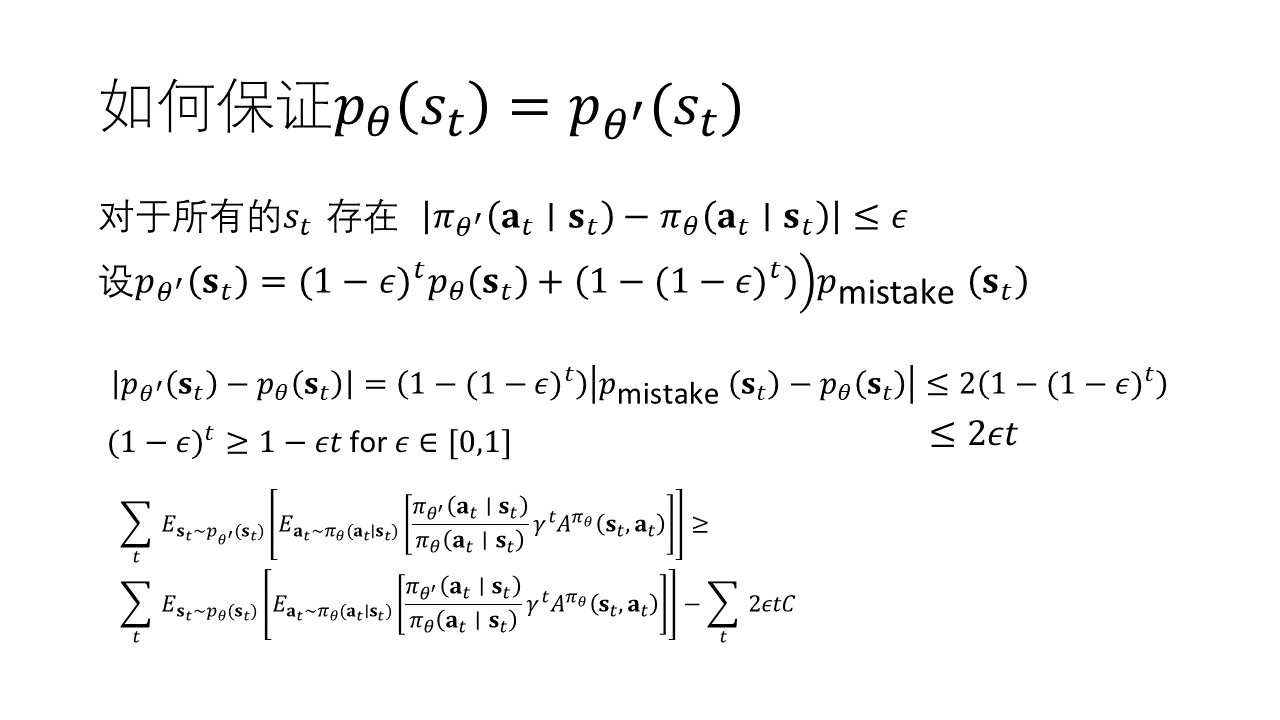
如何保证这个式子成立呢?若对于所有的存在,则能证明下的目标函数是下的目标函数的一个下界,且值越小,这个下界越严格。上图证明过程中的是相对于来说的,也就是以的概率满足分布,以的概率满足另一个分布。
信任域
如何保证对于所有的存在?通过推导我们终于引出了信任域,我们要保证在某个信任域下的能够满足上述限制。
这个信任域该如何取呢?
PG中的方法很简单,限制梯度更新的步长,它的信任域为为圆心,步长为半径的一个圆。这是一种对的简单限制。
TRPO中利用分布间的KL距离作为限制,由于不同参数对于目标函数的敏感度不同,TRPO通过Fisher矩阵将信任域变为一个基于不同参数敏感度的椭圆。
PPO中则利用clip限制参数的更新范围,从而限制。
这就是策略梯度方法共有的信任域选取问题,与他们不同的解决方式。