为了让计算机能运行程序,需要软件/硬件约定。
计算机在按下电源按钮后,会传递一个reset信号,硬件上会对CPU进行reset,规定每个寄存器中的初始值,其中包含PC。
整个计算机系统是一个状态机,系统从PC程序计数器出进行译码与执行,每次从PC中取出一条指令执行。硬件厂商会设置一个PC的初始值,那么只要在这个初始地址放置对应程序地址,再保证PC可以读到下一条指令,使得操作系统可以运行起来。
CPU reset后,PC=ffff0是一个确定地址,对应地址一般是一条跳转指令跳转到对应位置的Firmware厂商的软件,在ROM(只读内存)中写死的代码(Firmware),里面会配置启动系统顺序,超线程,硬件虚拟化,这个Firmware(固件),BIOS or UEFI。
Firmware 扫描系统硬件,寻找有操作系统的硬件,让操作系统接管,启动盘的前512字节是主引导扇区,要由Firmware搬运到物理内存的7c00位置。ABC三个盘中A与B是软盘。
BIOS将内存的7c00设为启动磁盘的前512MBR个字节,将PC同样指向这个位置。(LOADER)通过这些代码加载其他的代码,最终加载出操作系统。
键盘扫描获得扫描码,将扫描码放在缓冲区中并通知CPU发生中断。
CPU执行完一条指令后,发现中断寄存器为1,进入中断过程,通过IDT(中断记录表)映射交给键盘处理程序。
键盘处理程序会从缓冲区中将扫描码放在键盘缓冲区中,键盘处理程序将扫描码换为ASCII码。
之后进程通过系统调用取对应缓冲中字符,将ASCII码放入到显存中。
显示器控制程序不断将显存中的信息转化为显示的屏幕内容。
二、从键盘输入开始理解编码的存在形式
以window系统为例,假设你刚刚打开了记事本。
1.你在键盘上按下了’a‘。
2.你的按下触发了电路,键盘扫描到你a被按下,于是键盘形成了’a’的扫描码,发送到了存在于键盘上的寄存器,同时给CPU发送了一个中断信号,告诉CPU我这有活动了!
3.CPU根据键盘的中断线路号检测到是键盘发出的中断信号,于是根据中断号计算出键盘的中断处理程序在内存中的地址,转到键盘的中断处理程序去执行。
4.键盘的中断处理程序找到键盘的驱动程序代码,转到键盘的驱动程序执行。
5.键盘的驱动程序去读取键盘上的保存扫描码的寄存器,把‘a’的扫描码读到内存中。
6.驱动程序把扫描码转换成虚拟码。为什么要转换呢,因为不同的键盘由于厂家不同,型号不同、设计不同的原因,‘a’这个按键产生的扫描码在不同的键盘上是不一样的,为了统一管理,驱动程序得把不同键盘按下的‘a’转换成统一的表示。比如把不同键盘按下的‘a’产生的扫描码统一转换成一个字节的0x41。驱动程序要进行转换,那么驱动程序得知道这是哪种类型的键盘,不然没有转换的依据,原理是键盘的相关信息比如生产厂家、键盘型号等会保存在键盘上的一些只读寄存器中,计算机通过这些只读寄存器就知道这是哪种键盘。从而就知道该键盘的扫描码对应的虚拟码。
7.驱动程序把0x41交给操作系统上自带的且在后台默默运行的的IMM进程。
8.IMM进程把0x41交给系统当前使用的的输入法编辑器。比如搜狗输入法或者百度输入法。系统上所有的输入法,都由IMM管理。
9.输入法收到了0x41,对0x41进行处理,霹雳巴拉一顿操作,首先查到0x41这个值对应的可能的文字,比如可能是‘啊’、‘阿’、‘吖‘…等。首先查询系统当前的代码页是哪一个,也就是系统默认编码,若你没有修改系统的默认编码,则查找的结果为GBK(相当于GB2312)编码的。于是通过GBK的代码页这些可能的文字的GBK编码找出来,通过操作系统从字库中寻找这些可能文字的字库数据,交给显卡,显卡把他们显示出来。
10.显卡把他们显示出来后,屏幕上显示了好多个文字让你选择,那么你通过键盘的左移右移回车等操作选中了一个字,这个键盘操作又产生扫描码,最后还是输入法接收到了你的键盘按键输入情况,然后,输入法就可以根据你的键盘输入情况确定你选中了哪个文字,假设你选中了’啊’,于是输入法把‘啊’这个字的GBK码交给操作系统,操作系统把这个GBK码放进指定内存中,这指定内存被称为输入缓冲区。
11.记事本可以扫描缓冲区有没有内容,当检测到了缓冲区有了内容后,记事本至少需要两个操作,一是把‘啊’这个文字显示到记事本的窗口里面,二是把”啊”的编码放到自己的内存空间。
12.记事本接收到的是GBK编码,这个编码保存在了记事本的内存空间,并把“啊”输出到了记事本的窗口中。这时你的输入操作已经结束了(如果你不再进行输入),接下来就是保存这个记事本的内容了,如果想要保存这个“啊”,你的应用程序就得向操作系统申请一个文件,把“啊”的编码写进文件中。如果你不作任何操作,硬盘上就会默认保存的是‘啊’的GBK编码,如果你想保存的是’啊’的其他编码,那也可以,转换一下编码格式,然后放进文件中保存。放进文件中保存,那c语言来说,有二进制方式的写和文本文件方式的写,该用什么方式呢?首先说明什么是文本文件,文本文件就是保存文本的文件,里边都是一些字符(也就是文本)的编码,解析出来后都是文字,你用utf-8格式保存的,里边就是utf-8格式的字符的编码,你用GBK格式保存的,里边就是GBK的编码,总之里边保存的是文字信息。另一个就是二进制文件,一般来说我们编程很少用到。二进制文件里边保存到不是文本,比如视频文件、图片文件、3D模型等。其实二进制文件和文本文件在文件中的保存形式都是0和1的二进制流,既然都是0和1的二进制流,为什么要区分他们呢,因为他们有点区别,比如文本文件以EOF(值为-1)作为文件结束标志,因为不管是什么编码,都没有哪个字符的编码值是-1。而二进制流就不一样了,里边完全有可能有一段字节代表着-1,因此不能以-1作为文件的结束标志,一般来说二进制文件应该是通过比较文件长度来判断结束标志的。在c语言中,我们通常是使用fwrite()和fread()函数来读写文件,那么我们并没有指明以什么编码方式来读出或写进文件啊,别忘了,两个函数会是系统调用相关的,而系统默认的编码格式就是GBK,因此这两个函数都是按GBK来进行读或取的。如果你想使用其他编码比如UNICODE,就得使用其他读写的函数了,比如fgetwc()、fwscanf();这些函数会把GBK编码转换成UNICODE编码再进行读和写。
13.记事本默认保存的编码是ANSI,ANSI也叫多字节字符集,ANSI其实不是一种编码方式,是所有使用不定长字节来表示字符的编码格式的统称,在简体中文Windows操作系统上,ANSI指的是GBK编码,在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 JIS 编码。当然你用可以更改记事本的保存格式。Unicode同理,Unicode是一个字符集,不是一个编码方式,在windows这边,Unicode指的是UTF-16,在其他环境下,可能指的是UTF-8或UTF-32,比如linux上指的是utf-8.
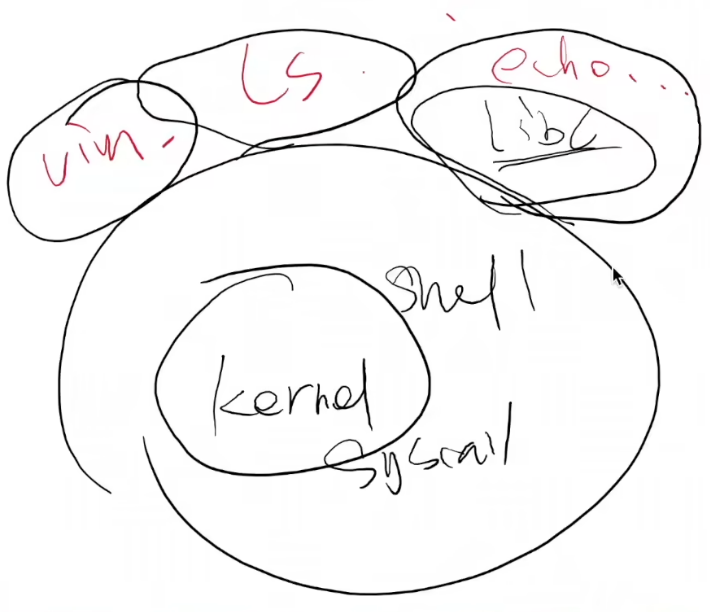
操作系统会加载第一个程序,可以进行系统调用创建新进程,操作系统中有一个进程init,init通过系统调用创造整个世界,中断/异常处理程序,挂载文件系统,创建新进程,内存管理,网络……。
系统调用,要么通过syscall进行同步,要么类似并发,系统cpu自旋。
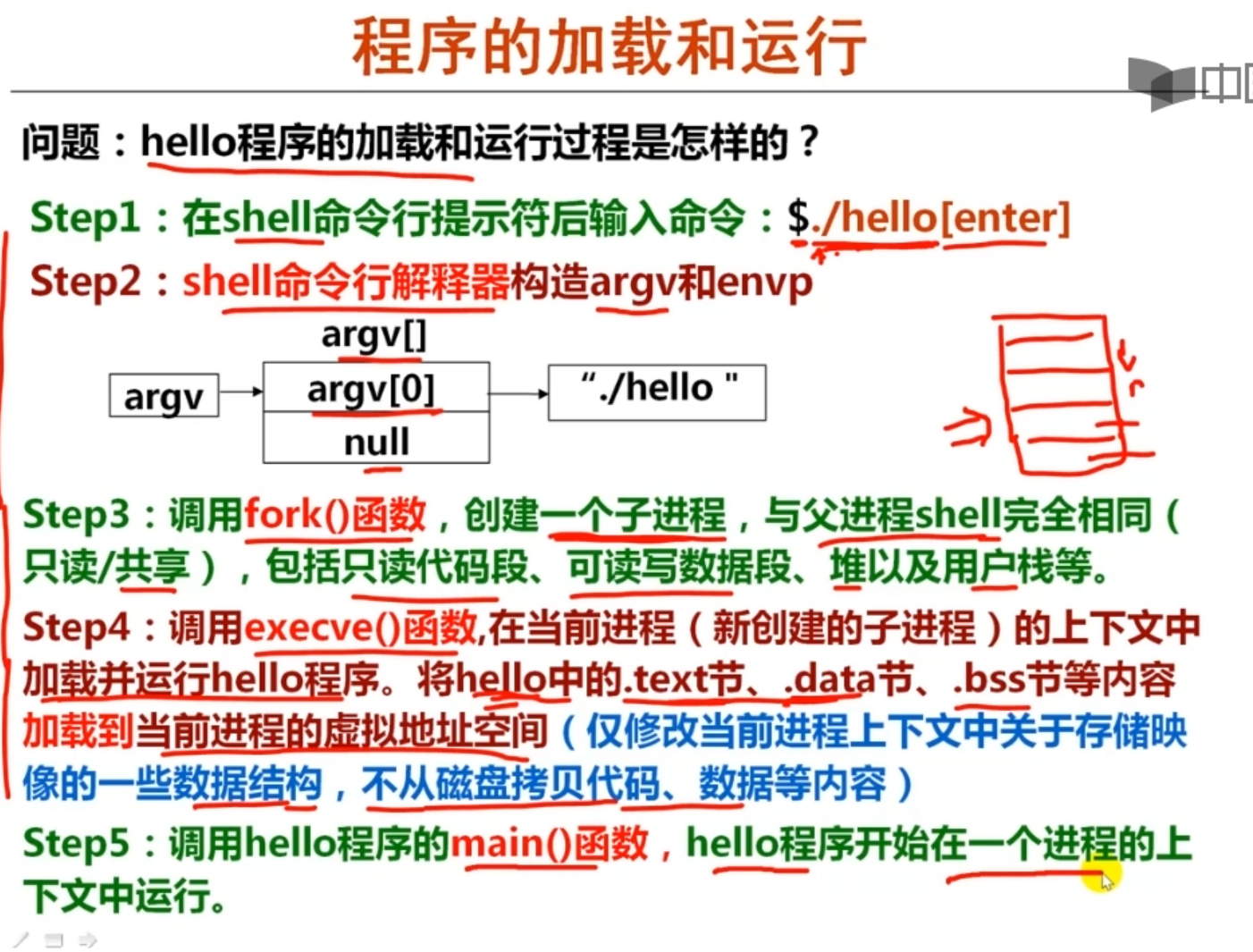
进程管理:fork,execve,exit
fork() 系统调用,生成另一个完全一样的进程副本(寄存器,内存中字节)都一样,除了fork的 返回值,每个进程都有一个编号,fork会返回它的子进程,子进程的fork会返回0。若只有一个 CPU,系统会选择一个进程执行一步。
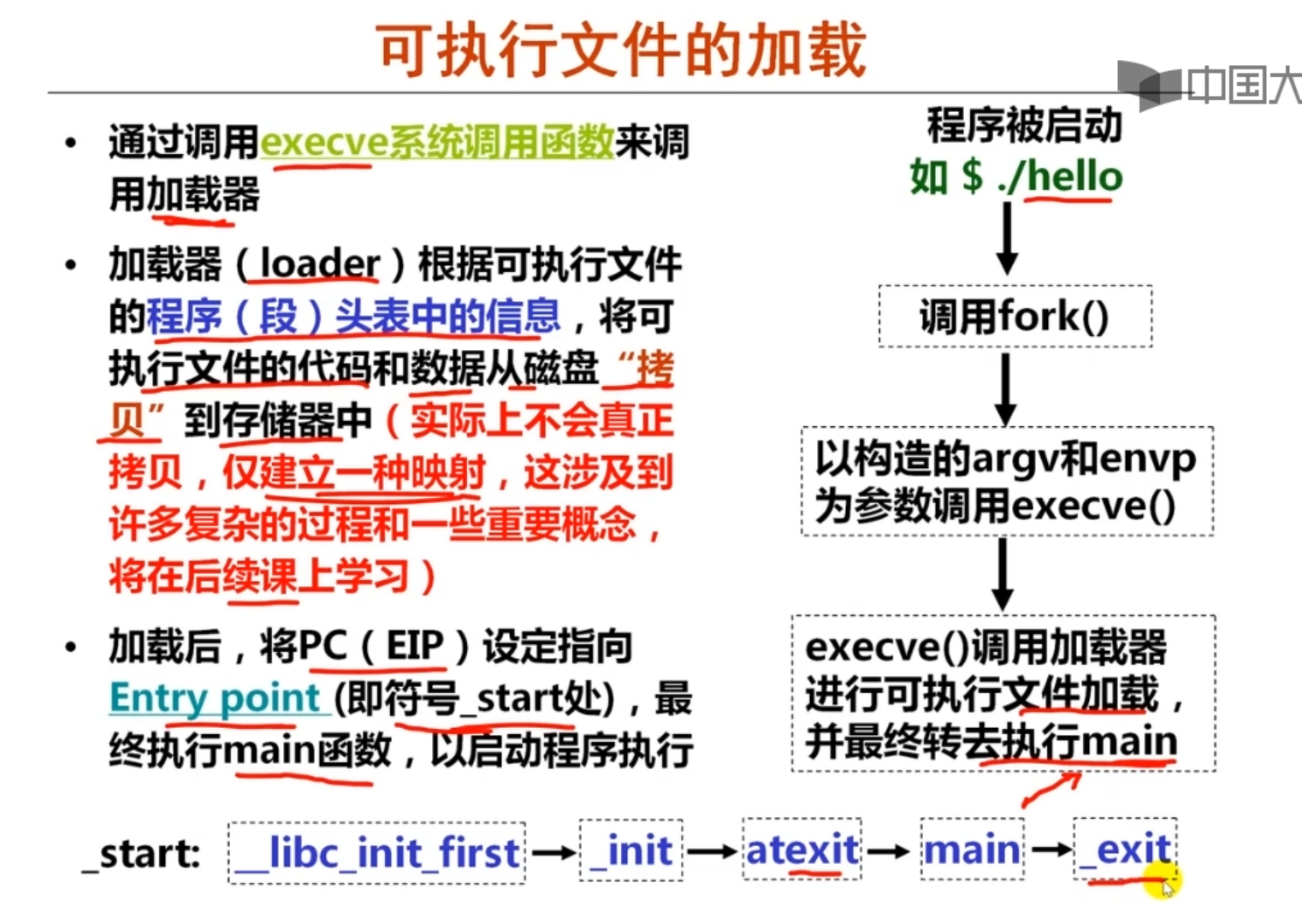
execve() 重置一个状态机为某个程序的初始状态,运行其他进程而不光是init进程 reset
exit() 结束进程
存储管理:mmap-虚拟地址空间管理
pmap查看内存空间会看到不同的段地址


vdso 非陷入系统调用
mmap:管理地址空间(分配/回收),把文件映射到内存空间
文件管理:open,close,read,write-文件访问
mkdir,link,unlink-目录管理
此时操作系统有一个Kernel用于实现系统调用,同时也要有Shell管理输入输出设备,Windows有Graphic shell
Shell就是一门把用户指令翻译成系统调用的语言,命令>树>系统调用
jobcontrol
ctrl C 产生的信号是由终端处理的,终端是设备。
在登陆启动shell后,会打开一个session,session中有很多进程组(shell是session leader也是其中的一个进程组,在运行其他程序时也会转为后台),进程组可以放在前台或后台,进程组中无论fork多少进程都有相同的groupid,因此在收到SiGINT后就会给相同groupid组中的进程发送信号。每个session会有一个终端,每个时刻只有一个进程组处于前台运行,此时终端产生的信号会传给前台进程组中每一个进程。
libc
在系统调用之上构建程序能够普遍受惠的标准库
标准库底层也是系统调用
封装系统调用,纯粹的计算,操作系统中对象(文件描述符),操作系统状态,内存管理
管道有一个读口 有一个写口,shell在建立管道后,会fork两个进程,分别改变他们的标准输入与输出
fork
fork+execve+pipe,fork在复制时会复制持有的操作系统对象,而execve在重置时会保留这些操作系统对象,因而父子进程可以通过管道连接
文件描述符:一个指向操作系统内对象的指针
进程实际不持有页面,所有页面本质上是操作系统的,进程支持有映射表
fork对于内存页面进行写时复制
fork 创建平行世界
可执行文件
execve(这里调用可执行文件):作用将当前状态机重置到可执行文件初始状态
可执行文件描述状态机
状态机=寄存器+内存(地址空间)+调试信息
状态机的转移和初始状态
链接
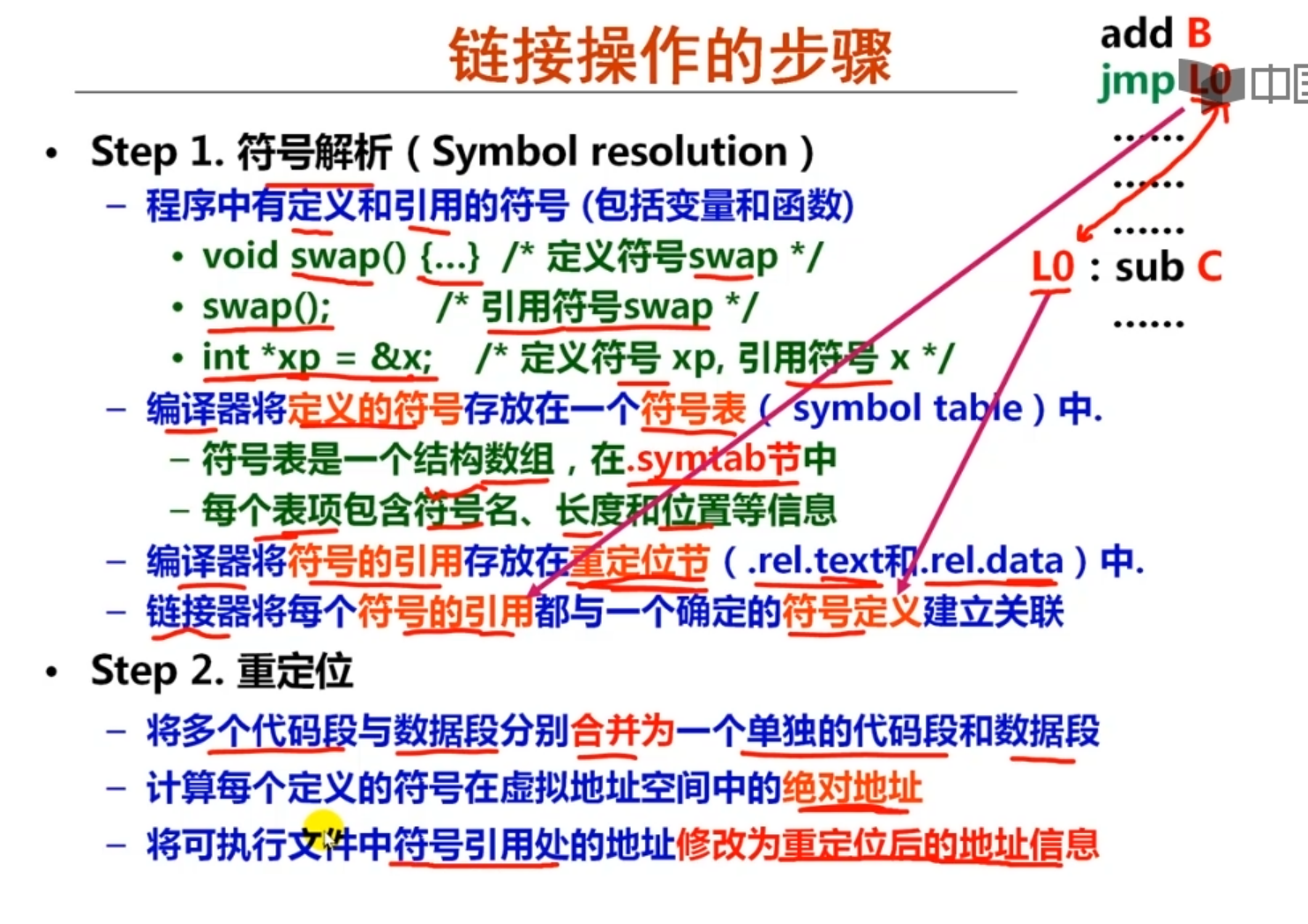
在连接前汇编中call指令之后的链接声明直接填0,但还要在链接后要将正确的地址填到call命令后
- C语言状态机 经过 gcc 得到指令状态机 经过assembler 数据结构+约束条件 经过链接器 满足所有约束条件


name比较浪费空间,所以用指向字符串常量池的指针代替

linux 设置x权限就会认为它是一个可执行文件
预处理器发现 #include 指令后,就会寻找指令后面<>中的文件名,并把这个文件的内容包含到当前文件中。被包含文件中的文本将替换源代码文件中的#include 指令, 就像你把被包含文件中的全部内容键入到源文件中的这个位置一样
stdio.h 到底引用的哪个位置的文件,进行预编译的时候可以使用-I定义预编译文件的目录,gcc -verbose中可以看到include search start中有默认目录与加入的目录。
预编译时 头文件会完整粘过来,头文件中的include也会粘过来,同时#开头的预编译指令都执行完,这个执行是一种完全的字符串处理,其实只需要extern一个函数声明即可以。链接器在链接时会处理函数到真正的地址。
define就是文本替换!
编译
将源代码编译成汇编代码
编译后时还是文本代码,汇编后时二进制的机器代码
python中会将先执行other.py中的所有代码,之后创建出一个模块对象,名字为other,并将所有的顶层变量以属性的形式绑定在模块对象上。引入import后的变量名称到当前命名空间。
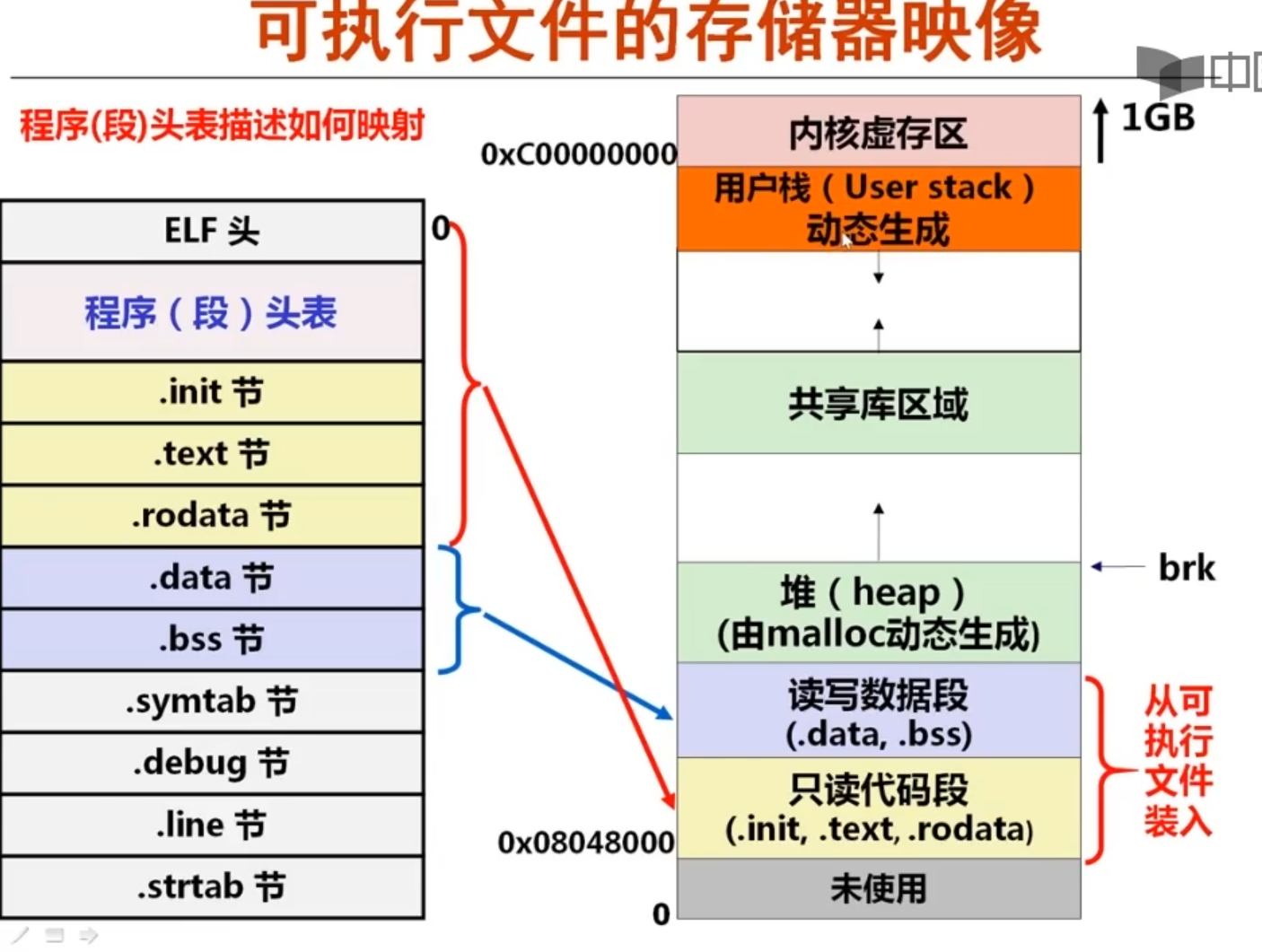
4.1 从编译和链接角度看ELF文件(可重定位目标文件)

从编译和链接角度看ELF文件ELF头
每个ELF文件都必须存在一个ELF_Header,这里存放了很多重要的信息用来描述整个文件的组织,如: 版本信息,入口信息,偏移信息等。程序执行也必须依靠其提供的信息。
段头表
段头表。存放的是所有不同段将在内存中的位置。
.text section
代码段。存放已编译程序的机器代码,一般是只读的。
.rodatasection
只读数据段。此段的数据不可修改,存放常量。比如,printf中的格式化语句。
.datasection
数据段。存放已初始化的全局变量、常量。
.bsssection
bss段。未初始化全局变量,仅是占位符,不占据任何实际磁盘空间。目标文件格式区分初始化和非初始化是为了空间效率。

从编译和链接角度看ELF文件.symtabsection
符号表,它存放在程序中定义和引用的函数和全局变量的信息。
.rel.txtsection
.text节的重定位信息,用于重新修改代码段的指令中的地址信息。
.rel.datasection
.data节的重定位信息,用于对被模块使用或定义的全局变量进行重定位的信息。
.debugsection
调试用的符号表。
.strtab section
包含 symtab和 debug节中符号及节名。